As a certified nerd, I sometimes get early access to pre-public technology. It's part of the social nature of success with technology, early adopters try something out. Companies get feedback and user insights, users get a edge on the latest and greatest. That can drive incorporation into their future products and spheres of influence.
A few days ago, I got access to Google Labs' Search Generative Experience. And I am smitten. All the buzz about ChatGPT AI often overlooks the fundamental challenges of artificial intelligence. Among those, understanding good sources of information from bad as well as knowing when to stop talking.
In other words, ChatGPT and others like it are Large Language Models. They essentially process the known published material on the internet and produce a response based upon the most likely next thing in a series of language samples related to that context. Meaning that if 51% or more of the articles about a topic are slanted to one interpretation, expect the LLM to mirror that interpretation. The larger the dominance of opinion in topic-driven material on the internet, the more likely the LLM is to ignore the existence of the minority opinion.
Moreover, the world recently learned that some Large Language Models are actually being supported by humans who restate the question in terms the LLM will better understand. And what if they only direct topics to one opinion either by implicit bias or by corporate instruction?
Philosophical questions that society needs to start understanding and asking before there is universal embrace of AI engines.
So what's different about Google SGE? Well, for starters, it's built atop the best existing index of web content available.
And it also seems to understand its limits.
Perhaps the best way to explain is to share some examples from my test drives of it.
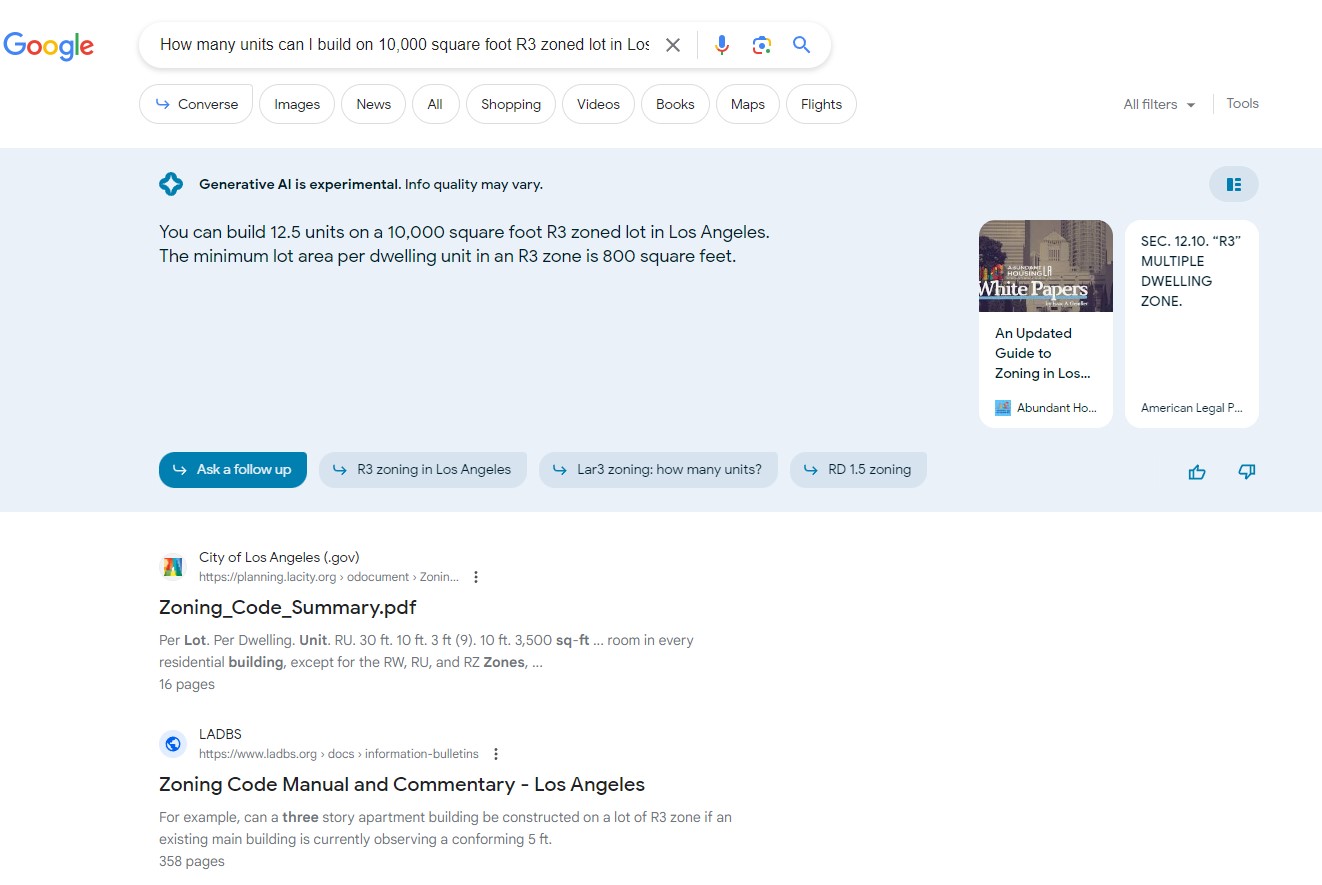
I asked it a fairly simply zoning utilization question about a generic lot and zoning. Its response was correct albeit without the appropriate rounding. And it was readily obvious where to find official information as well as the sources the response relied upon.
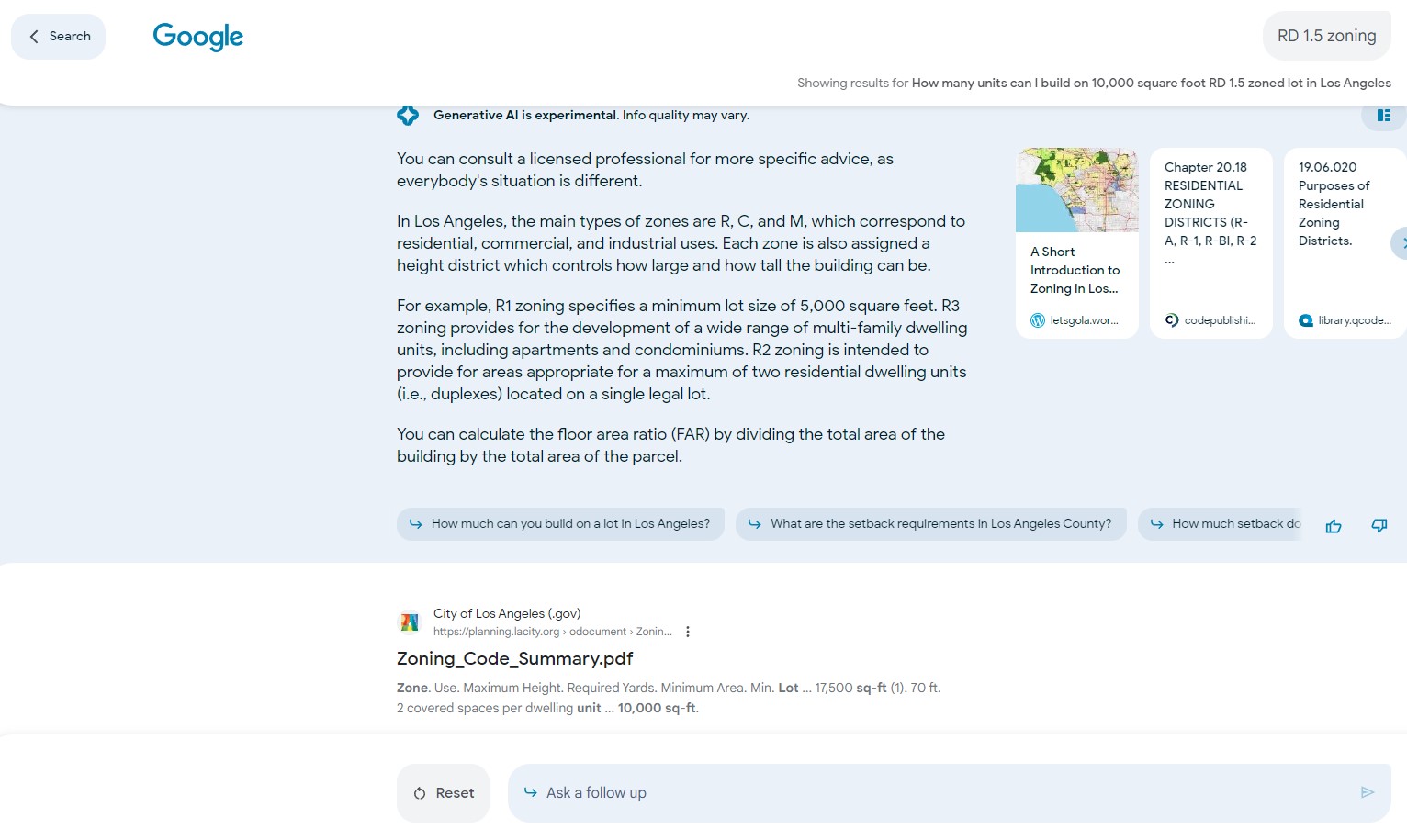
A day later I asked it a question about two other zoning types -- RD1.5 and R5. Now it responded with a caveat regarding consulting a professional (always a wise idea) and did not provide a utilization analysis as it did with R3.
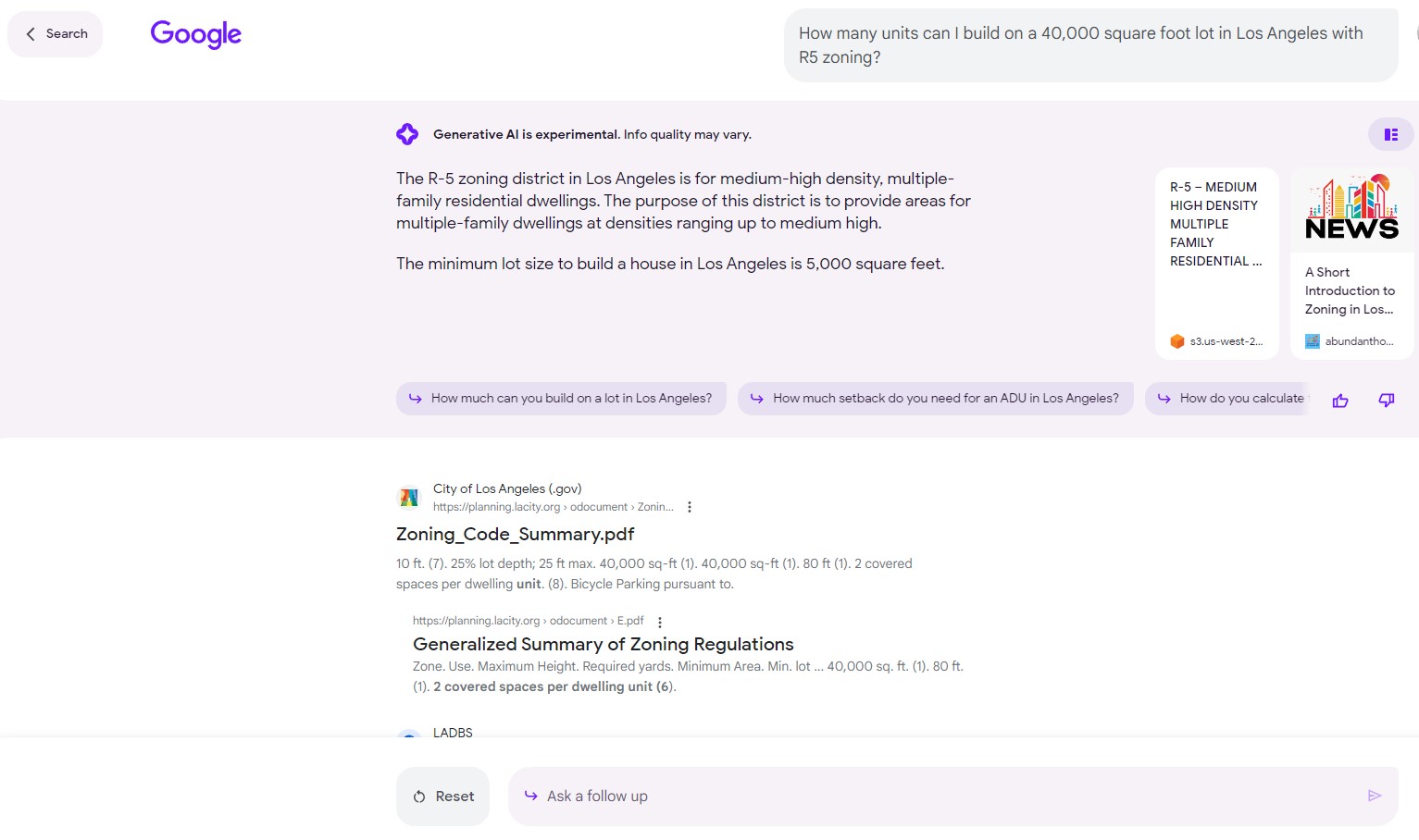
It gave a weaker answer for R5 -- Los Angeles' most dense multifamily zone -- and provided neither a caveat to consult a professional nor a unit yield count.
I initially searched for information on Single Family Residential by looking at APNs for properties near the Shakespeare Bridge in Los Feliz. The system did not recognize individual parcel numbers as well as it did for street addresses.
Presumably this is because the internet is more populated with property information driven by address:
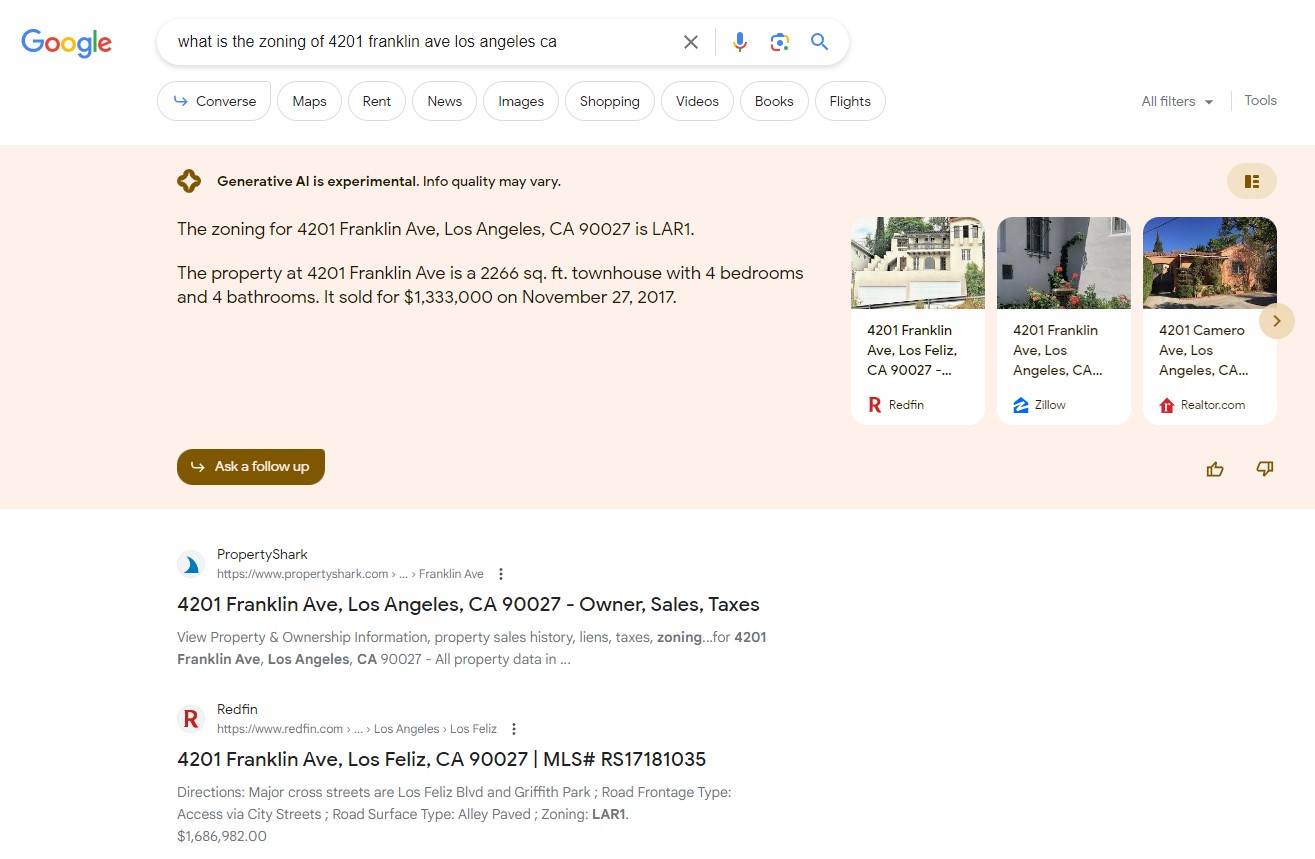
The information in the responses appears to be coming from a property's prior sales listings rather than official sources. And critical details like ownership information never surfaced in several different bites at the apple.
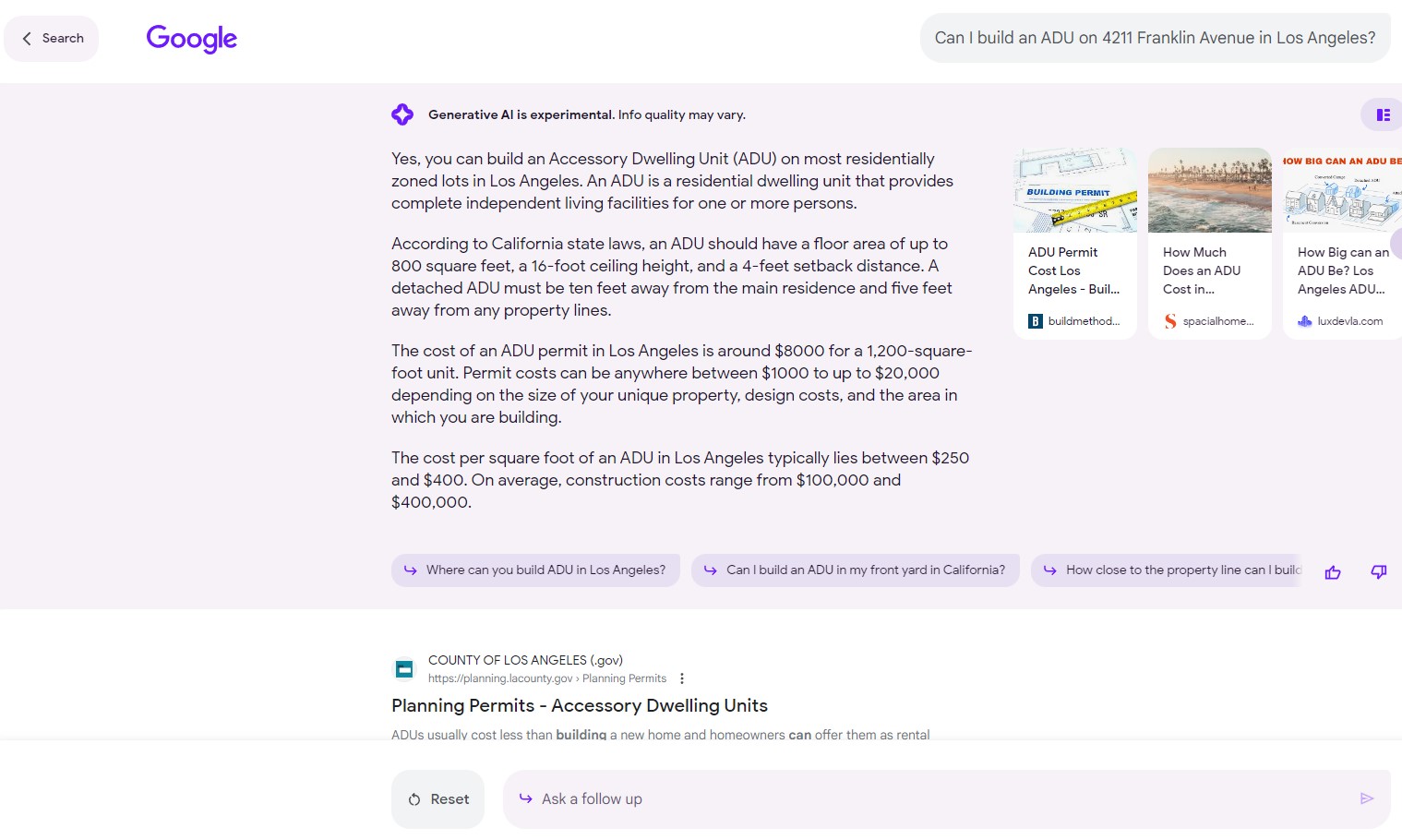
It's also not ready to take information like zoning, lot size, and structure size to complete a calculation like ADU eligibility that it must find as well:
Where this Generative AI engine appears to truly perform its best is in summarizing Big Data.
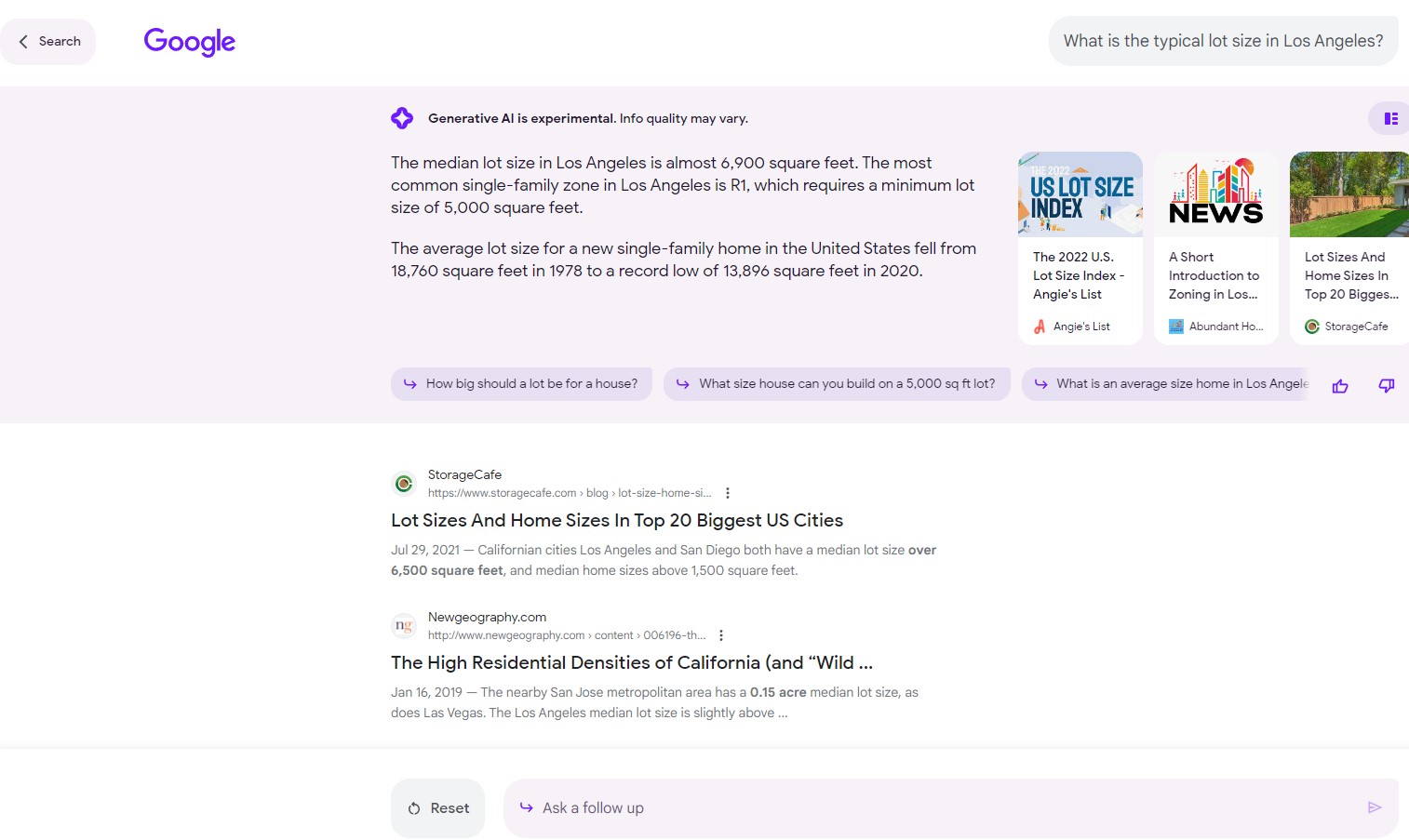
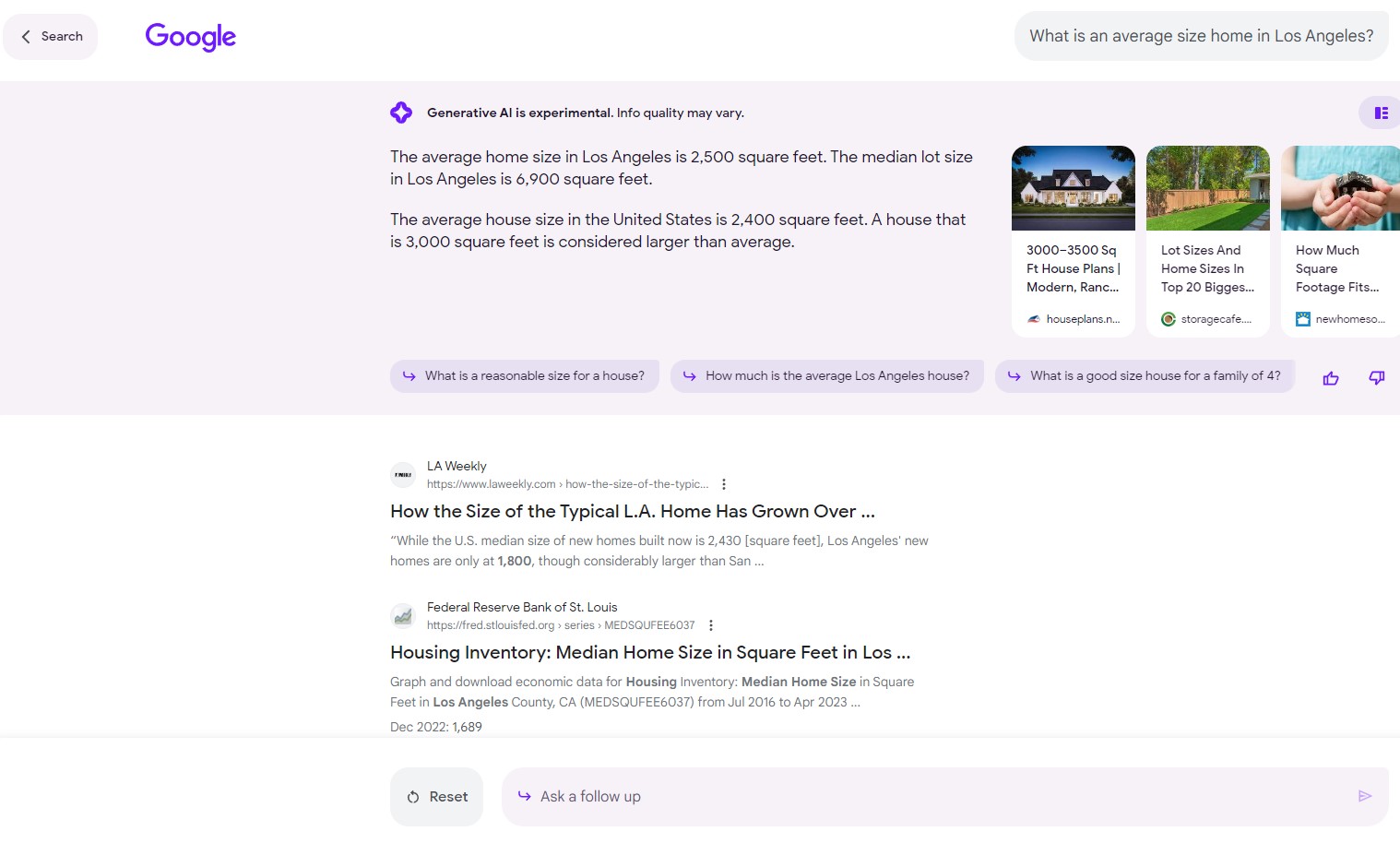
Here with technical information like typical lot size and typical home size in a given market:
And, impressively, here with an overview of industrial land use in Southern California -- citations in the response as well as a specific example from one city followed with a general statement on land use policy formation:
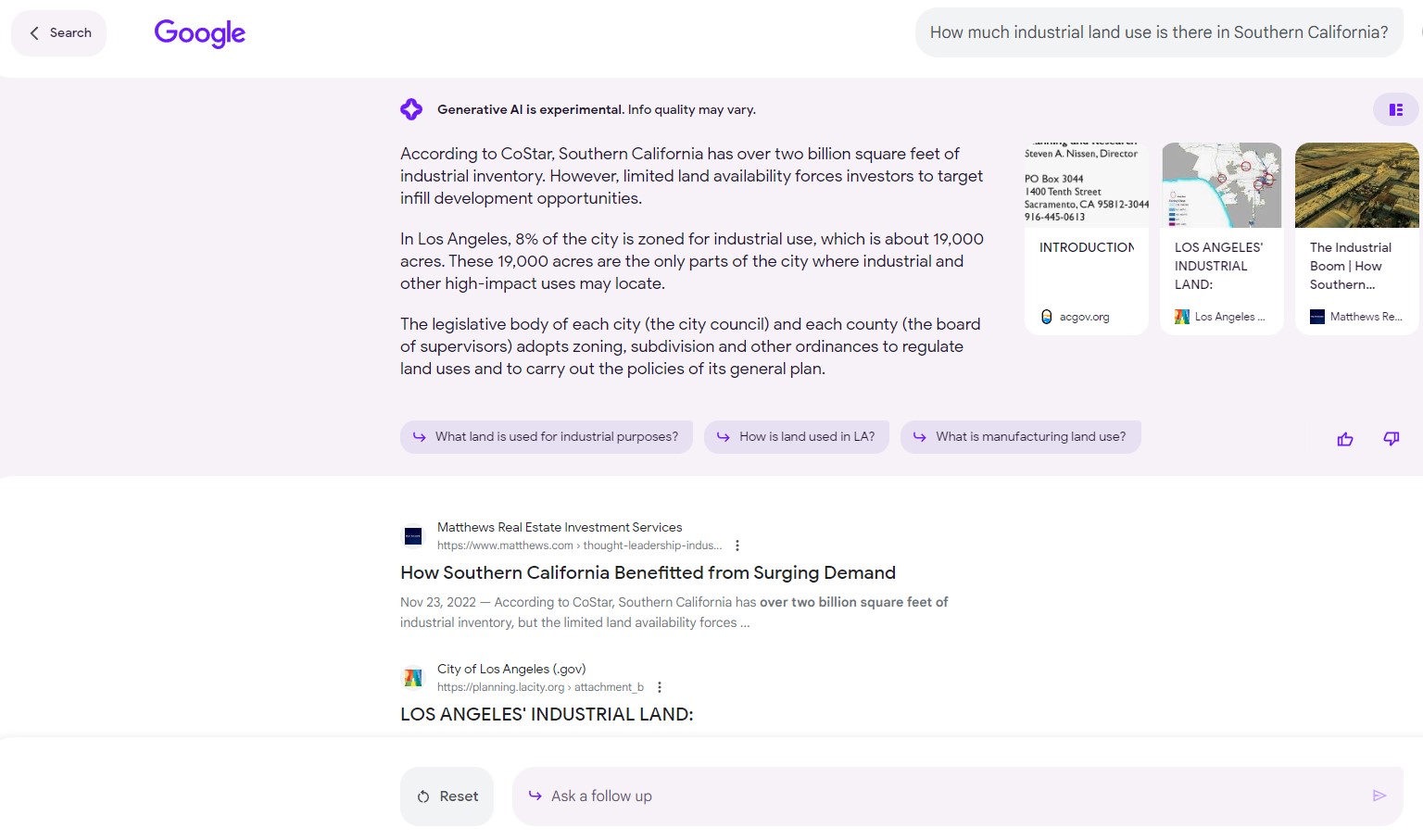
Overall, Generative AI is a welcome addition to Google's dominance in web search.
Google Labs' SGE experiment is expected to run until the end of 2023. After that, I'd look for Google SGE to become a mainstream integration in early 2024.
At that point, Google may become more of a knowledge engine than a search engine...tbd
